Planning initial installation and master configuration
Introduction
Data One is a distributed, clustered, highly modular product that requires some planning before actually installing it on one or, more typically, multiple physical or virtual machines.
The recommended approach to installation planning is:
- Design the deployment topology, i.e. defining where to deploy which components.
- Provision machines with the correct prerequisites for the components they are designated to host.
- Provision database resources dedicated to the product.
- Configure existing network apparatuses - such as load balancers and firewalls - to correctly handle all the new network connections that will be established by the product once installed.
In the next few sections we provide comprehensive information enabling a system administrator to correctly plan Data One installation.
Data One runtime services, nodes and components
Data One is a modular and distributed product. Depending on business requirements, some of its optional components will not be required. On the other hand, the adopted components can be distributed across target machines in different ways in order to meet specific non-functional requirements.
Data One Installation Manager (DOIM)
DOIM is a mandatory CLI component that handles the installation of the product on a set of managed nodes - that will be collectively referred to as Data One Domain nodes - and the management of the associated Domain Master Configuration (DMCFG), i.e. the bootstrap configuration that enables the product services to startup.
After the initial installation and configuration, DOIM is used to deploy changes to the master configuration and to deploy product updates and fixes.
DOIM CLI offers a number of different commands that operate on Data One both at domain and node level, i.e. whose scope spans some or all nodes in the domain (see also doim.sh reference).
The node where DOIM itself is installed is called control node and it's always the first one to be set up, given that it will then drive the installation on the rest of Data One domain nodes.
Data One control node is not very resource hungry and does not host a long-running runtime service. The only user interaction with DOIM is DOIM CLI.
DOIM is the only part of Data One product that is not operating in a clustered mode, i.e. only one such node is required to perform the required actions through DOIM CLI.
The picture below describes the two deployment options for control node designation, and consequently for DOIM deploy.

Control node designation options
Either option is acceptable, and even in case Option 1 is adopted, control node does not need a dedicated physical or virtual server, just a dedicated O.S. user and enough disk space is sufficient.
When Option 2 is adopted, it is required that DOIM and the actual Data One product are run in two different users. This is required to keep distinct operational contexts even if the physical or virtual server is shared between the two users.
The main non-functional traits of DOIM and the associated control node are:
- the node must be regularly backed up as it stores vital domain state information including:
- installable product base image
- installable product updates and fixes images
- master copy and version history of DMCFG
- enough free disk space to store additional product updates and fixes as they are released over time
- availability of a specific version of Ansible and python (see System Requirements for more details), that are used to orchestrate commands across different domain nodes
Central Manager (CEMAN)
CEMAN is a mandatory platform component that oversees all data integration command and control tasks, including the choreography and orchestration of actions on one or more STENGs nodes. Moreover, CEMAN hosts the platform-wide Data One administrative WUI.
A CEMAN node embeds three main components that are typically not accessed directly by users and administrators:
- CEMAN-Core: the core component serving core APIs, administrative WUI and supporting core data integration orchestrations and choreographies
- AMQ Brokers: Artemis ActiveMQ brokers underpinning all the core communications between distributed Data One components
- IAM Server: core Keycloak-based server providing Identity and Access Management (IAM) services to all distributed Data One components
CEMAN operates in clustered mode, for both scalability and availability purposes. One of the key deployment decisions is how many instances of CEMAN to deploy, a typical number covering most production scenarios is 3 CEMAN nodes (3 being the smallest odd number greater than 1).
On each CEMAN cluster node a single instance of all embedded components (namely: CEMAN-Core, AMQ Brokers and IAM Server) will be running.
The main non-functional traits of CEMAN are:
- need of a high speed connection with the Data One database
- need of a fast shared file system across all cluster nodes, to hold AMQ Brokers message store and other critical state information
- need of sufficient RAM and CPU resources to cope with workload peaks
Data Watcher Engine
Data Watcher is an optional platform module in charge of storing and managing all events emitted by the platform as well as other 3rd-party monitored systems, in order to perform end-to-end dataflow monitoring.
A Data Watcher node running Data Watcher Engine embeds three main components that are typically not accessed directly by users and administrators:
- MongoDB: an embedded document-oriented database, mainly used as an event store.
- Apache Storm and its prerequisite Apache Zookeeper: used to process streams of events emitted by the platform or other 3rd-party monitored systems.
Data Watcher operates in clustered mode, for both scalability and availability purposes. One of the key deployment decisions is how many instances of Data Watcher to deploy, and where to deploy them.
A typical number covering most production scenarios is 3 Data Watcher nodes (3 being the smallest odd number greater than 1) deployed on the same nodes hosting CEMAN clustered instances.
On each Data Watcher cluster node, a single instance of all embedded components (namely: MongoDB, Apache Storm and Apache Zookeeper) will be running.
The main non-functional traits of Data Watcher are:
- need of a fast local file system, to hold MongoDB event store, with enough free space to cope with the expected events volumes and required event retention
- need of sufficient RAM and CPU resources to cope with event peaks
Scalable and Trusted Engine (STENG)
STENG is a mandatory platform component in charge of performing executive data integration tasks, choreographed or orchestrated by CEMAN.
STENG operates in clustered mode, for both scalability and availability purposes.
Managed file transfer (MFT) tasks are an example of the tasks performed by STENG.
A member of a STENG cluster is also referred to as STENG Peer, or simply Peer.
One of the key deployment decisions is how many STENG Peers to deploy, and where to deploy them.
A typical number covering most production scenarios is 2 to 5 STENG Peers deployed on dedicated nodes, selected in way that optimizes access to the user data that must be locally processed (e.g. the user file system where files must be read/written) or remotely processed (e.g. the remote servers accessed via SFTP or other protocols, where files must be read/written).
The main non-functional traits of STENG are:
- STENG is mainly network-bound and I/O-bound, and just moderately CPU-bound
- STENG requires high performance access to local and remote data producing systems and data consuming systems
- STENG needs sufficient RAM and CPU resources to cope with workload peaks
DMZ Gateway
DMZ Gateway is an optional platform component that enables the deployment of multi-tiered MFT architectures where:
- business files are streamed through the DMZ without actually being staged on DMZ storage at any time
- business data integration configurations are dynamically injected into DMZ at runtime, without being persisted on DMZ storage at any time
- the firewall between DMZ and the intranet is only traversed in the intranet-to-DMZ direction for both incoming and outgoing file transfer protocol connections, using secure session tunneling techniques
DMZ Gateway operates in clustered mode, for availability purposes. One of the key deployment decisions is how many instances of DMZ Gateway to deploy, and where to deploy them.
A typical number covering most production scenarios is 2 DMZ Gateway nodes (an active one and a failover one) for each DMZ segment where a STENG node needs to expose its services through DMZ Gateway.
DMZ Gateway can be seen as a "logical proxy" to STENG for MFT scenarios where secure one-way DMZ traversal is required.
The main non-functional traits of DMZ Gateway are:
- DMZ Gateway totally network-bound
- DMZ Gateway footprint on DMZ storage is negligible as no business data or business configurations are ever persisted on it
Data Shaper Engine
Data Shaper is the data transformation solution of the Data One platform. It provides quick and flexible any-to-any data transformations.
Data Shaper operates in clustered mode, for both scalability and availability purposes. One of the key deployment decisions is how many instances of Data Shaper to deploy.
The deploy location of Data Shaper is predetermined by existing deployment of STENG. In fact, the Data Shaper Engine can be exclusively installed on nodes that already host a STENG Peer. Depending on the expected load, Data Shaper Engine can be installed on all STENG Peers or on just a subset of them.
The main non-functional traits of Data Shaper are:
- Data Shaper is typically I/O-bound, due to the need of reading and writing the data to be transformed
- Depending on the types of transformations that must be performed, Data Shaper can also be CPU-bound
Data One Platform Modules vs Data One Platform components
In section What is Data One? you have learned about Data One platform modules (namely Data Mover, Data Watcher and Data Shaper), while in the previous sections you have learned about Data One platform components.
Once your initial business requirements are defined, it should be clear which Data One platform modules you are going to need. The table below describes which Data One platform components you will need to deploy for each module.
| Component name | Data Mover | Data Watcher | Data Shaper |
|---|---|---|---|
| DOIM | ✓ | ✓ | ✓ |
| CEMAN | ✓ | ✓ | ✓ |
| Data Watcher Engine | optional | ✓ | optional |
| STENG | ✓ | ✓ | ✓ |
| DMZ | optional | n/a | n/a |
| Data Shaper Engine | optional | optional | ✓ |
This information can then drive the selection of the best deployment pattern fitting your needs.
Data One common domain topology patterns
In the next few sections we discuss Data One topology patterns, i.e. typical ways of deploying Data One platform modules across all domain nodes.
While the reported scenarios are recurring and typical, by no means they cover all the allowed combinations. So, your actual production topology may differ from the reported ones, due to environment-specific functional / non-functional requirement or constraints.
Note: DOIM and control node are not depicted for simplicity reasons, but clearly a node playing the role of control node and hosting DOIM must always be present and capable to connect to all other nodes in the domain, as explained at the beginning of this chapter.
1-tier (single node) - Data Mover (with DMZ), Data Watcher and Data Shaper
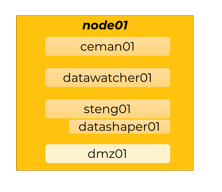
In this topology pattern, a single machine runs one instance of all these components:
- CEMAN
- Data Watcher
- STENG
- Data Shaper
- DMZ
This topology pattern is mainly meant for experimentation and testing purposes, as it lacks the scalability and availability typically required in production environments.
On top of that, running DMZ on the same machine as STENG, although technically feasible, voids DMZ of its proxying architectural role, which makes it useless.
2-tiers - Data Mover, Data Watcher and Data Shaper
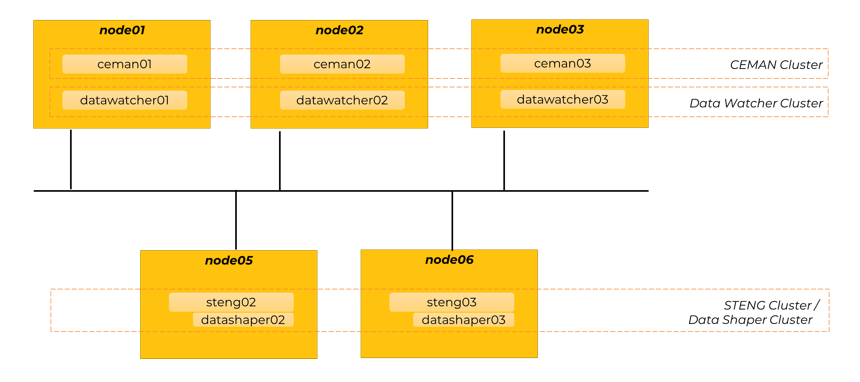
In this topology pattern, components are distributed across two tiers of machines, each of which independently clustered and scaled, more precisely:
- Tier 1 - Command & Control and Monitoring Tier, made of 3 machines, each of which running on instance of these components:
- CEMAN
- Data Watcher
- Tier 2 - Executive Tier, made of 2 machines, each of which running one instance of these components:
- STENG
- Data Shaper
This pattern is typically adopted for MFT-oriented scenarios.
3-tiers - Data Mover (with DMZ), Data Watcher and Data Shaper
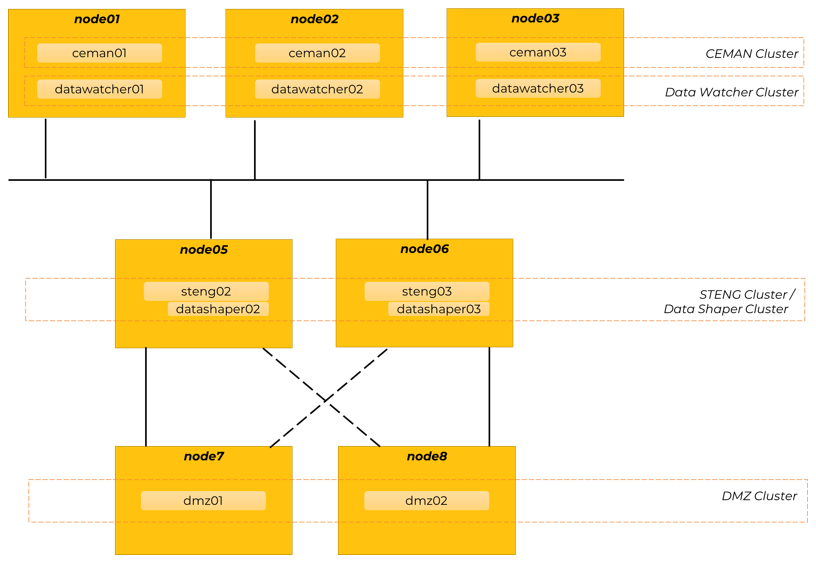
In this topology pattern, components are distributed across three tiers of machines, each of which independently clustered and scaled, more precisely:
- Tier 1 - Command & Control and Monitoring Tier, made of 3 machines, each of which running one instance of these components:
- CEMAN
- Data Watcher
- Tier 2 - Executive Tier, made of 2 machines, each of which running one instance of these components:
- STENG
- Data Shaper
- Tier 3 - Proxying Tier, made of 2 machines, each of which running one instance of this component:
- DMZ
4-tiers - Data Mover (with DMZ), Data Watcher and Data Shaper
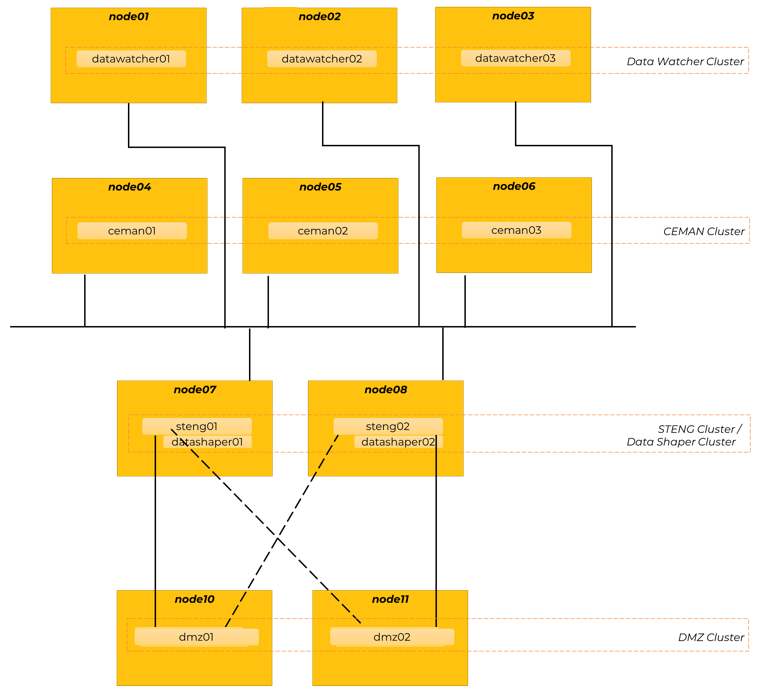
In this topology pattern, components are distributed across four tiers of machines, each of which independently clustered and scaled, more precisely:
- Tier 1 – Monitoring Tier, made of 3 machines, each of which running one instance of this component:
- Data Watcher
- Tier 2 - Command & Control Tier, made of 3 machines, each of which running one instance of of this component:
- CEMAN
- Tier 3 - Executive Tier, made of 2 machines, each of which running one instance of these components:
- STENG
- Data Shaper
- Tier 4 - Proxying Tier, made of 2 machines, each of which running one instance of this component:
- DMZ
Updated over 1 year ago