Data Partitioning (Parallel Running)
This chapter describes way to speed up graph runs with help of data partitioning.

Data partitioning is available in Data Shaper Server. It is not available in local projects.
What Is Data Partitioning
Data partitioning runs parts of graph in parallel. A component that is a bottleneck of a graph is run in multiple instances and each instance processes one part of the original data stream.

The processing can be further scaled to Cluster without modification to the graph.
Partitioned Sandboxes
In Data Shaper Cluster, you can partition files with temporary data to multiple Cluster nodes using Partitioned sandboxes. A file stored in a partitioned sandbox is split into several parts. Each part of the file is on a different Cluster node. This way, you can partition both: processing and data. It reduces amount of data being transferred between Cluster nodes.
When to Use Data Partitioning
Data partitioning is convenient to speed up processing when:
-
components communicate over the network with high latency (HTTPConnector, WebServiceClient);
-
some components are significantly slower than other components in a graph.
Way To Speed Up Processing
The way to speed up the run is to partition the data and run the slow component in parallel.
Designer and Server
In Designer and Server, you can speed up processing with copying the slow component and running it in parallel.

Scalable Solution in Data Shaper Server and Cluster
There is a better solution that avoids copying components and is scalable.
Set allocation to the components positioned between the Cluster components: right click the component and choose Set Allocation.

In Component Allocation dialog choose By number of workers and enter the number of parallel workers.
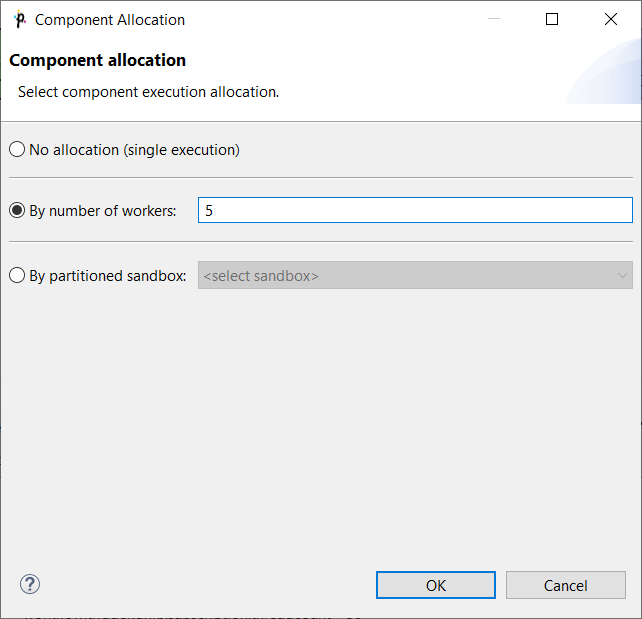
Components in your graph will contain text denoting the allocation.

How Does the Data Partitioning Work
Data partitioning runs part of a graph in parallel. The number of parallel workers is configured without copying the components. Data-partitioned graphs can take advantage of Data Shaper Cluster without modification.
Benefits of Data Partitioning
-
Clean design, no duplication. Avoid copying parts of graph to speed-up the processing. Set the number of parallel workers with a single option.
-
Scales to Cluster. You can use the same graph on a multi-node Cluster without any additional modifications.
-
Maximize use of available hardware. Take advantage of parallel processing on multi-core processors.
Things to Consider when Going Parallel
-
When you run some component in parallel, you should be aware of limits of hardware and other systems.
-
If you run parallel a component that does many I/O operations (e.g FastSort), you may be limited by speed of hard drive.
-
If you run parallel a component that opens many files (e.g FastSort), you may reach limit on number of opened files.
-
If you run parallel a component that connects to a web service, you may reach the limit of parallel connections to the service or run out of the quota on number of requests.
-
Consider other jobs running on server. Too many jobs running in parallel may slow down run of other graphs.
-
Some tasks cannot be easily parallelized.
Updated over 1 year ago